13 January 2020
roadmap
austria
What is AI and why should lawyers care?
Artificial intelligence (AI) and machine learning are familiar buzzwords when it comes to future technology and fundamental societal shifts. But what is it really all about and why is it so difficult to apply common legal concepts to these developments?
According to most widespread definitions of AI, an algorithm is considered artificially intelligent if
- it takes input from its environment;
- it interprets and learns from such input; and therefore,
- provides output which has a maximum likelihood of being correct.
Thus, an AI-algorithm is required to improve its behaviour by itself based on data it receives from its environment. Machine learning is therefore a crucial part of the process of creating AI, but is not synonymous with it. The steady increase in available computing power has made machine-learning-based AI applications reasonable solutions to an increasing number of problems, including search algorithms, image enhancement and automated translation applications, but also safety-critical applications like self-driving cars, medical diagnosis or malware detection.
Unlike ordinary programs, in which all parameters of the algorithm must be predefined (and just mirror the prior knowledge of a human), in machine-learning-based AI solutions certain parameters are found by the program itself as it learns from a given set of input and known results (training data). A separate (and mostly crucial) learning algorithm slowly tries to adapt the original algorithm's parameters for its output to best (or most likely) match the already known aimed output values of the training data.
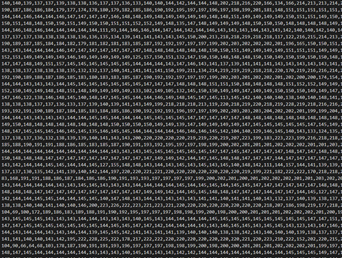
For example, defining a set of rules or patterns pursuant to which the AI algorithm could identify a bouquet of flowers (as shown in figure 1) in any given picture, might be rather inefficient, since such patterns would have to be defined for any given matrix of pixel values. The exact properties of the arrangement of pixels that our human visual cortex would identify as a bouquet of flowers could hardly be defined in any possible variety. A proper AI algorithm trained with a sufficiently large set of training data can offer an efficient solution to this problem, modelling its parameters to "pay attention" to the most significant properties of a bouquet of flowers in any picture.
Humans will easily make out a bouquet of flowers in figure 1. However, defining this concept in terms of the pixel values seen in figure 2, as received by any program, is difficult for humans and thus a classical problem for machine-learning-based AI.
Although the resulting individual parameters of a trained algorithm can be retrieved, how exactly such algorithms make decisions often remains a mystery (especially neural networks type algorithms). Thus, the resulting logic of the program mostly remains a "black box" to humans and only provides for the output of the highest probability to be correct (based only on past training data). This is one reason why legal issues relating to decisions made by AI tend to become complex and difficult to resolve, particularly based on "traditional" legal concepts and case law.


Alexander
Pabst
Attorney at Law
austria vienna